Being able to dynamically scale infrastructure is no longer a nice-to-have – it is a requirement. The advent of cloud and container platforms have shifted the expectations in terms of consuming IT infrastructure and services. As a result, any tool that is used to manage infrastructure needs to be able to handle this ever-changing landscape.
Red Hat Ansible Automation Platform provides customers with the tools that they need to build an automation solution. The component automation controller helps enterprises automate and scale with confidence.
One of the ways we can scale our automation is to leverage container groups. Container groups are part of automation controller, and allow customers to leverage an existing OpenShift cluster to create on-demand execution capacity for Ansible Playbooks. When a job is executed from automation controller, it creates pods on the target OpenShift cluster, which runs the automation job. Once the job is complete, the pods are terminated. This provides a number of benefits:
- Fewer wasted resources – infrastructure isn’t sitting idle while waiting for automation jobs. Once a job completes, the resources are instantly freed up.
- Deliver execution capacity quicker – we don’t need to provision infrastructure up front.
- Less focus on capacity planning – Red Hat OpenShift provides a pool of resources that can be controlled with limits and quotas as opposed to having to develop a number of virtual machines up front.
Let’s look at how we can leverage container groups within automation controller.
Preparing Red Hat OpenShift
Before we can start using container groups in automation controller, we need to create a namespace and service account in Red Hat OpenShift. The following example uses Red Hat OpenShift and the oc command line tool.
First, we will create a new namespace – this namespace will be used to launch the pods that will run our automation jobs.
|
$ oc new-project ansible-automation Now using project “ansible-automation” on server “https://api.comet.demolab.local:6443”. |
Next, we need to create a service-account and assign permissions. The following example creates a service-account called “aap-sa” and assigns the “edit” role to the service account.
|
$ oc create serviceaccount aap-sa serviceaccount/aap-sa created $ oc adm policy add-role-to-user edit -z aap-sa clusterrole.rbac.authorization.k8s.io/edit added: “aap-sa” |
The last step is to retrieve the token for our service-account that we will need for automation controller:
|
$ oc serviceaccounts get-token aap-sa <token> |
Configuring automation controller
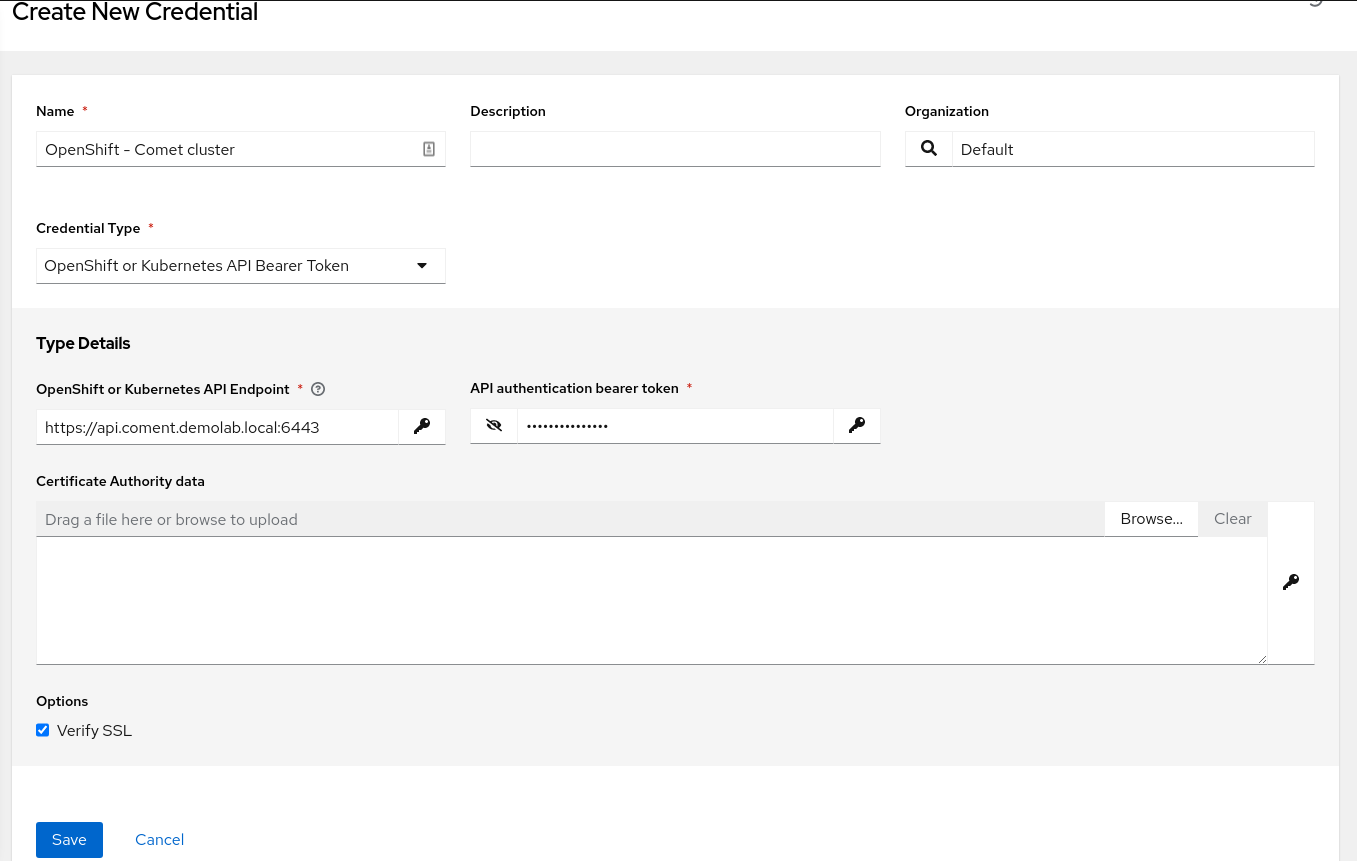
The workflow for creating container groups in automation controller is simple. First, we need to create a credential like “OpenShift or Kubernetes API Bearer Token”. This will allow automation controller to authenticate to the target OpenShift cluster to launch on-demand execution capacity. Enter the API endpoint for the OpenShift cluster and paste the token that we obtained from the service account secret.
Within the Ansible Automation Platform dashboard, under Resources -> Credentials, click the blue Add button. Fill in the details as follows:
The next step is to create the container group in automation controller. Navigate to Administration -> Instance Groups, select Add ->Add container group.
Enter a name for the container group and associate the credential we just created. Check the box to “Customize pod specification” – we want automation controller to create pods in our “ansible-automation” namespace. If we don’t edit the namespace, it will attempt to use the default namespace in Red Hat OpenShift. This would cause an issue, as we don’t have permissions to use the default namespace with our service account.
Modify the custom pod spec for the container because the execution environment associated with the Project, Inventory or Job Template will take precedence. If none are specified, it will use the default automation execution environment within automation controller. The configuration should look as follows:
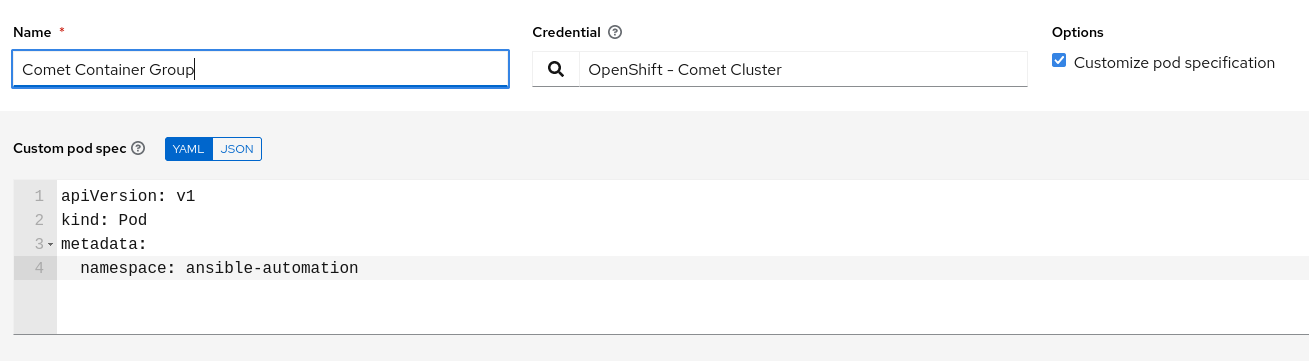
Once the changes have been made, click Save.
Testing the configuration
In order to use a container group, we must assign them to an inventory, project or job template. To test the configuration, let’s assign our container group to a job template.
There are a couple of fields that we need to pay special attention to in the Job Template. First is the “Execution Environment” field, which specifies the container image that will be used for the execution of the playbook. Here is the job template definition including the Execution Environment – Note the use of the “Minimal execution environment”. We’ll confirm later on that this is the image used during the job execution.
The second parameter we need to edit is the container group from the “Instance Group” option in the job template:
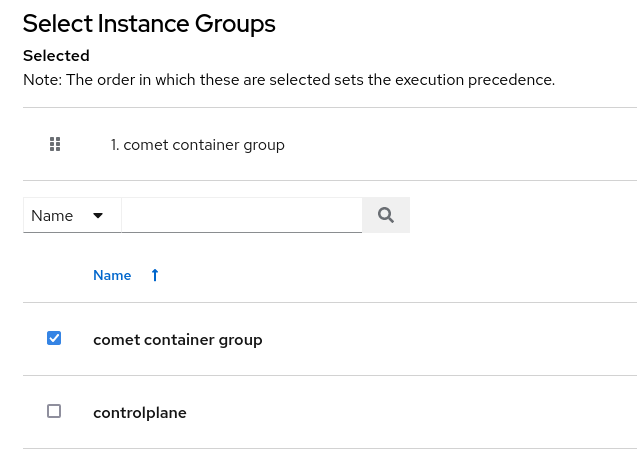
Now let’s launch the job! We can monitor the activity from the OpenShift platform to see what happens. Once the job starts running we should see a pod in our namespace:
|
$ oc get po NAME READY STATUS RESTARTS AGE automation-job-2010-scm85 1/1 Running 0 11s |
If we “describe” the pod, we can also verify the image that is being used for the execution. Remember we specified the minimal image:
|
$ oc describe po automation-job-2010-scm85 Containers: worker: Container ID: cri-o://fbdd50bb0c22c763e3e95497848515a2999646f542033f36a6d0e7fe80bf1f4c Image: registry.redhat.io/ansible-automation-platform-20-early-access/ee-minimal-rhel8:2.0.1 |
Once the job completes, the pod should terminate. Great! We can now spin up execution capacity for our Ansible jobs on-demand.
Taking it the next level with job slicing
Container groups can be combined with job slicing to further scale our automation. Job slicing distributes a single automation job across multiple execution nodes. Let’s take an example where we are automating against 1,000 virtual machines. To run this automation job on a single execution node could take some time to complete and we might not even have enough capacity to complete the job.
If we slice the job across five execution nodes, then each would be responsible for automating against 200 virtual machines as the target inventory of 1,000 virtual machines is distributed across each of the execution nodes.
Let’s go back into our job template definition and increase the number of slices to three by editing the “Job Slicing” parameter:

Let’s launch the job again and see what happens this time. You’ll notice that a workflow is automatically created for us. Each of the templates in the workflow represent a slice of the job.
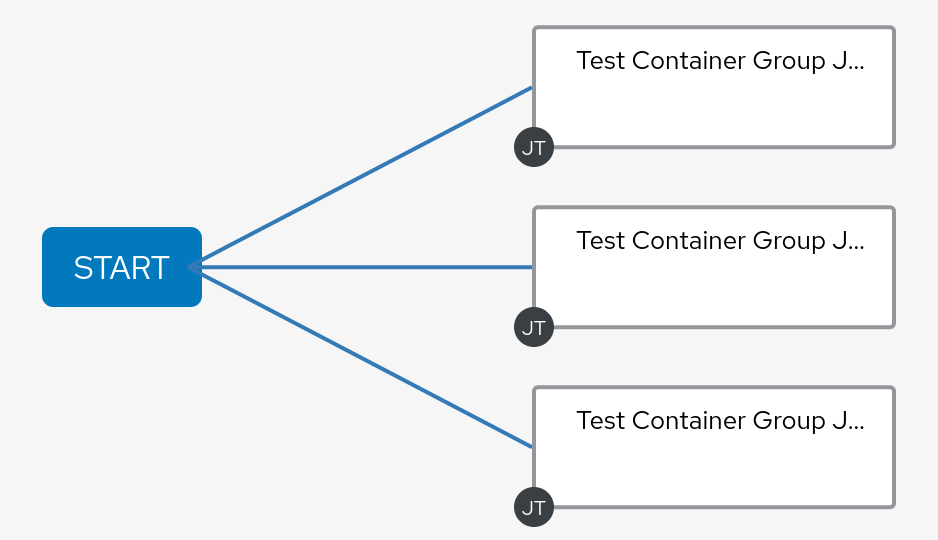
If we look in our OpenShift namespace we can also see that there are three pods running this time – with the job distributed across them:
|
$ oc get po NAME READY STATUS RESTARTS AGE automation-job-2033-558f9 1/1 Running 0 27s automation-job-2034-zk7sw 1/1 Running 0 27s automation-job-2035-lln9s 1/1 Running 0 27s |
Next Steps
Automation controller provides a platform for executing Ansible automation, and provides powerful features for scaling automation to meet the needs of large and complex enterprise customers. In this example, we saw how we can combine two of these features – container groups and job slicing – to provide a means for dynamically scaling automation by leveraging an existing OpenShift platform.
![]()
Originally posted on Ansible Blog
Author: Patrick Harrison