
When scaling automation controller in an enterprise organization, administrators are faced with more clients automating their interactions with its REST API. As with any web application, automation controller has a finite capacity to serve web requests, and web clients can experience degraded service if that capacity is met or superseded.
In this blog, we will explore methods to:
- Increase the number of web requests an Red Hat Ansible Automation Platform cluster can serve.
- Implement best practices on the client side to reduce the load on the automation controller API to improve performance and uptime.
We will use automation controller 4.2 in our examples, but many of the best practices and solutions described in this blog apply to most versions, including Ansible Tower 3.8.z.
Use cases that cause high-volume API requests
In this section, we will outline some of the use cases that can drive a high volume of API requests. In the recommendations section, we will address options to improve the quality of service at the client, load balancer, and controller levels.
External inventory management
In some use cases, organizations maintain their inventory in an external system. This practice can lead to a pattern of creating an inventory in automation controller for each job they want to run, and adding hosts via the API one at a time. This pattern does not scale well when this is a high-frequency activity and inventories are large, because it is slow for the client and can consume a large portion of automation controller’s capacity to serve API requests. An alternative solution explored in the recommendations section is to import hosts via inventory plugins.
Launching jobs and understanding results from external systems
Organizations that use Ansible Automation Platform to automate tasks may trigger automation from other systems that contain business logic or procedures that are external to the platform. These include commonly used orchestration tools like ServiceNow, HP Server Automation, HP Network Automation, BMC BladeLogic, etc.
For example, an organization may use a ticketing system like ServiceNow to create requests for certain tasks or provisioning and trigger a job in automation controller based on that external workflow. The system may then poll the automation controller API looking for updates to the status of the job to reflect this to the client. Rapid polling of the API can put undue stress on the system and consume automation controller resources for serving web requests. We explore options to ease this load on the system while meeting end user needs in the recommendations section.
Short maintenance windows
Organizations may need to perform certain tasks during a maintenance window. In automation controller, time based schedules or webhooks from GitLab or GitHub are the main ways to automate launch jobs during a maintenance window. Because these methods do not meet all use cases, users may manage the business logic of when the maintenance window begins and what jobs should be run in an external system. This external system then launches jobs via the API, but may do so in a suboptimal way. We explore multiple options to optimize this workflow in the recommendations section.
Recommendations to optimize API performance
In this section, we will explore three types of recommendations.
- Modifications that can be made to the user workload to optimize their use of automation controller’s resources.
- Modifications at the load balancer level to better mediate API requests across automation controller cluster nodes. At the load balancer layer, administrators can manage request volumes and limit service degradation, as well as give informative error messages that recommend workload modifications to improve performance.
- Once organizations have optimized their automation controller API service interaction based on the client-side recommendations, we will look at modifications to the automation controller deployment itself, and ways administrators can scale its total capacity to serve clients.
Modifications to user workloads
Import hosts via inventory plugins (custom or built-in)
An alternative solution to using single host inventories is leveraging built-in inventory plugins or custom inventory plugins and using variables that can be used to modify their output. For example, if hosts are in AWS, the AWS inventory source in automation controller uses the AWS inventory plugin from the amazon.aws.aws_ec2 – EC2 inventory source. The blog post Configuring an AWS dynamic inventory with automation controller explores using variables to only select certain hosts or generate custom groups based on instance information from the AWS API.
If inventory needs are not covered by built-in inventory plugins functionality, additional inventory plugins can be sourced from Ansible Content Collections or developed by the team and used in automation controller sourced from a project. See the documentation on Inventories at Inventories — Automation Controller User Guide.
Execute jobs against multiple hosts when possible
Running automation tasks against multiple hosts simultaneously as a single job improves automation controller resource usage. When jobs act on multiple hosts, automation controller’s ability to serve API requests and job scheduling mechanisms don’t limit the amount of target hosts that can be automated concurrently.
When many small jobs are created for each target host, the number of job launches and ongoing API requests increase as the number of managed hosts grow. Additionally, scheduling a job takes time, and the platform has limits on how many jobs can be scheduled in a short period of time.
Additionally, grouping the tasks you want to run on multiple hosts into a single playbook reduces automation controller API requests. You can delegate which playbook tasks should run on specific hosts using inventory group membership and Ansible facts. Some users create single host inventories due to the perception that this method makes it easier to understand the job results on a per-host basis. However, understanding the results on a per-host basis doesn’t require single-host inventories. The automation controller API includes features to gather job result data for individual and multiple hosts. To access data for all the hosts for a specific job (<JOB_ID>), use the API endpoint:
api/v2/jobs/<JOB_ID>/job_host_summaries/This endpoint returns a summary for each host and how many tasks failed, changed, or were successful.
Alternatively, if instead of wanting to know only the results from one job, you need to know the results for all jobs against a specific host, use:
/api/v2/hosts/<HOST_ID>/job_host_summaries/ This API endpoint provides a summary of all the jobs run on a specific host (<HOST_ID>) and includes the same job output data described in the previous example. This type of summary data of tasks failed, changed, and ok for each host is also included in the data sent to webhook endpoints for success/fail notifications using webhook notifications.
In summary, executing jobs against multiple hosts can reduce load by decreasing the number of requests made to launch the jobs without sacrificing any ability to track the status of hosts or to fetch results.
Limit rapid polling of API for status updates
The automation controller REST API is not designed to support rapid polling, and does not do any type of batching of requests or caching of results. Each request will result in a database query. For this reason, large scale rapid polling is not advisable as it is quite resource intensive, and in general, if jobs take at least 30 seconds to complete, polling every 1 to 5 seconds is excessive.
As an alternative to rapid polling of a job for status updates, users can first implement a type of backoff in their polling. This results in waiting for increasing periods of time between each GET to the API at each iteration. For example, poll 5 seconds, then 10, then 20, etc.
A more sophisticated solution may include implementing a webhook service where automation controller can send data when the job completes. The documentation for webhook notifications outlines how automation controller can post job status data, such as job progress, success and failure, to external web services in JSON format. This is especially important if there is a requirement to distinguish results on a per-host basis when a job is run on multiple instances simultaneously. Additionally, the job data output can include additional information using customized messages.
Load Balancing
If your deployment has multiple control plane nodes, a load balancer should be configured to redirect traffic to these nodes, and clients should use the load balancer as ingress to automation controller API and UI.

Load balancing controller WebUI and API requests
Load balancers allow for web requests to be spread across multiple control plane nodes, as well as provide a set of features to moderate client behavior. In these examples, we provide links to HAProxy documentation, but these features are common to other load balancers such as F5.
Rate-limiting
Load balancers should be configured to rate-limit bad-actor clients. HAProxy provides a set of features that allows a number of rules to trigger rate-limiting, as explored here. When the client hits the limit based on different rules, they receive a 429 HTTP return code that communicates to the user that they have been rate-limited.
A rate-limiting feature that automation controller administrators should consider is setting “max_connections”. Load balancers can be configured to set max connections per control plane node. We suggest starting at 100 maximum connections per automation controller, and adjusting it within a range of 50-200. If there are slow average request times, reduce the number of “max_connections” or, alternatively, increase the “max_connections” if the average request time is satisfactory.
See this blog for HAProxy examples. Other load balancers have similar options.
Also explored in the above HAProxy blog is rate-limiting based on certain URL patterns. For automation controller, administrators should consider rate-limiting specific URLs like:
- POST to /api/v2/job_templates/d*/launch which causes jobs to be launched
- POST to /api/v2/inventories/d*/hosts/ which creates hosts in an inventory
For Ansible Tower 3.8.z and prior, administrators should additionally consider rate-limiting GET requests to the endpoints that access job_event data. This type of data (essentially the output of the jobs) can create a large table that is expensive to query. The URL patterns are:
- GET to /api/v2/job_events/
- GET to /api/v2/jobs/d*/job_events/
In automation controller 4.0 and later, this table is partitioned at the database level and has become cheaper to query and clean up.
Health Checks
Load balancer administrators should consider both active and passive health checks.
Passive health checks check the return code of actual live requests. Operational problems on individual automation controller nodes can cause 502/504 errors if underlying services are unhealthy. In this case, administrators would want the load balancer to be able to automatically take a control node out of circulation for serving API requests.
Check out this blog for information on HAProxy.
Automation Controller Deployment Modifications
Horizontally scaling the control plane
Automation controller administrators can horizontally scale the number of control nodes in the cluster and update their load balancer configuration to distribute API requests across these nodes.
Automation controller administrators can monitor /var/log/supervisor/awx-uwsgi.log for messages indicating that the application server is operating at maximum capacity. This can be used to decide whether to decrease the number of “max_connections” on the load balancer or to horizontally scale the number of automation controller nodes to maintain the quality of service (QoS) for clients.
Scaling the number of automation controller nodes would allow more requests and lowering the number of load-balancer “max_connections” in combination with rate-limiting would preserve the QoS for existing clients, but prevent more requests from being made. Note that there is a maximum supported number of nodes in the cluster as documented for the version of automation controller or Ansible Tower. For automation controller docs, see the automation controller clustering documentation. For Tower 3.8 see Ansible Tower Clustering Documentation.
Example /var/log/supervisor/awx-uwsgi.log message indicating uwsgi is at maximum busyness:
[busyness] 3s average busyness is at 100% but we already
started maximum number of workers available with current limits (16)
Adjusting automation controller instance capacity
If it is desirable to prioritize API request servicing over job execution by control nodes, the “capacity_adjustment” feature (visible as a slider on individual instances) can be set to the “CPU” based capacity calculation. This can also help compensate for jobs that create large amounts of output that the control nodes must process with the callback receiver, which is also CPU intensive.
To use this feature in the API, set the attribute “capacity_adjustment” to 0 on instances at:
a/api/v2/instances/<ID>/Setting it to 0 is equivalent to sliding the capacity slider to the left in the UI when looking at instances in an instance group, as illustrated below. Note that this will reduce the number of concurrent jobs the instance will run.
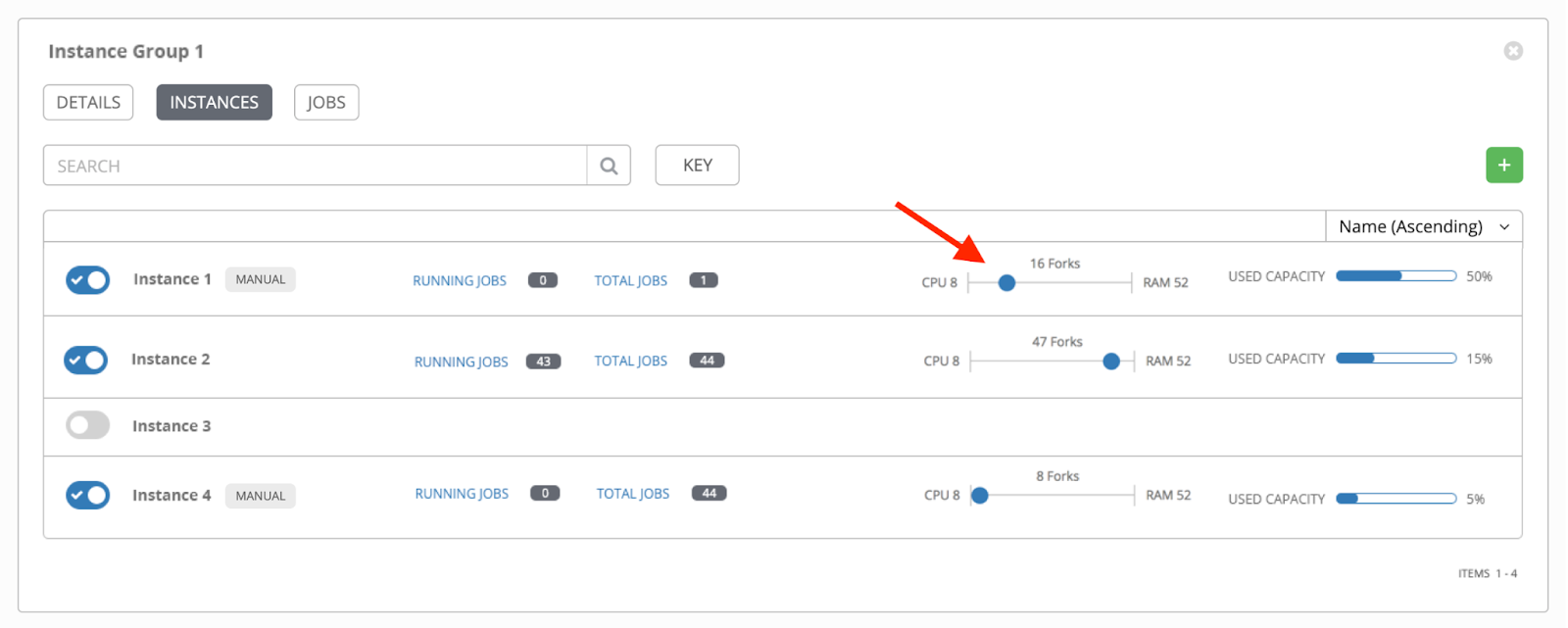
Automation controller capacity adjustment feature
Summary
Automating with automation controller’s REST API can be extremely useful and productive. Applying best-practices to automation controller and user workflows enables a consistent, quality service as your Ansible Automation Platform grows. These best practices include optimal automation controller configurations and improving the method clients consume the API.
Where to go next
Whether you are beginning your automation journey or a seasoned veteran, there are a variety of resources to enhance your automation knowledge:
- Self-paced exercises – We have interactive, in-browser exercises to learn and dive into Ansible Automation Platform.
- Trial subscription – Are you ready to install in your environment? Get your own trial subscription for unlimited access to all the components of Ansible Automation Platform.
- Subscribe to the Red Hat Ansible Automation Platform YouTube channel. Be sure to check out our new web series, Automated Live hosted by Colin McNaughton.
Follow Red Hat Ansible Automation Platform on Twitter – Do you have questions or an automation project you want to show off? Tweet at us!
Acknowledgements:
Edward Quail
Nikhil Jain
Thanh Nguyet Vo “TVo”
![]()
Originally posted on Ansible Blog
Author: Elijah Delee