Cloud-native deployments are becoming the new normal. Being able to keep full control of the application lifecycle (deployment, updates, and integrations) is a strategic advantage. This article will explain how the latest release of the Ansible Content Collection for Red Hat OpenShift takes the redhat.openshift Collection to the next level, improving the performance of large automation tasks.
Red Hat OpenShift collection at a glance
The latest release of the redhat.openshift Collection introduces Ansible Turbo mode. Ansible Turbo mode enhances the performance of Ansible Playbooks when manipulating many Red Hat OpenShift objects. This is done by reusing existing API connections to handle new incoming requests, removing the overhead of creating a new connection for each request.
A real-world scenario
Red Hat OpenShift has become a leading platform that can handle many workloads in large enterprises dealing with multi-tenancy clusters. These are great candidates when different users, teams, and/or organizations are looking to run and operate in a shared environment.
One of the best features of Red Hat OpenShift is the capability to quickly and easily create and destroy resources (e.g., namespace, ConfigMaps, Pod). Even with relatively light usage, deploying each one of them separately could be an arduous task and more so when the application needs to be deployed to more than one OpenShift cluster. In this scenario, the number of distributed objects can suddenly become unmanageable, slowing operational responsiveness and increasing the probability of dangerous mistakes.
This scenario is typical through the phases of a Continuous Integration and Continuous Delivery (CI/CD) pipeline, which may need a temporary and isolated environment to perform integration testing. A typical process includes:
- creating namespaces
- populating resources to support the testing process
- removing the resources once the testing phase is complete
To further increase the complexity of the scenario, some of the tasks in the CI/CD pipeline require either loading specific configurations from ConfigMaps or storing the state of the resulting execution to be shared with other tasks.
Benchmarking: breaking down the numbers
This leads to the question, how does the increase in distributed objects impact the performance of an OpenShift cluster? To test the impact of Turbo mode, we ran a simulation that quantifies how much time these tasks take to run without Turbo mode enabled and then calculates the difference with Turbo mode on.
To support our benchmarking, we will run the following environment:
- A Red Hat OpenShift Cluster (3 control nodes, 3 worker nodes) on AWS using OpenShift Container Platform 4.8
- An AWS EC2 instance that serves as the management server from where we ran the OpenShift installer and CLI tasks
The main focus of the benchmark playbook is to run a specified number of tasks that include:
- Deploying OpenShift objects (namespace or ConfigMaps) into the cluster.
- Deleting the OpenShift objects (namespace or ConfigMaps).
- Collecting performance metrics
For those interested in testing the benchmark in their environments, the code used to provision the Red Hat OpenShift Cluster on AWS is all available on GitHub, in the Provision a Red Hat OpenShift Cluster on AWS repository. Similarly, the code that was used to do the benchmarking can be found in the Benchmark Scripts for community.okd Collection repository.
All tests ran under Ansible 2.10 and Python 3.8. The performance metrics have been collected using ARA Ansible plugins. To appropriately appreciate the performance of Turbo mode, we performed a scalability analysis as a function of the number of namespaces and ConfigMaps created (e.g., 100, 500, and 1,000). The benchmark playbook was run five times and the performance metrics were averaged.
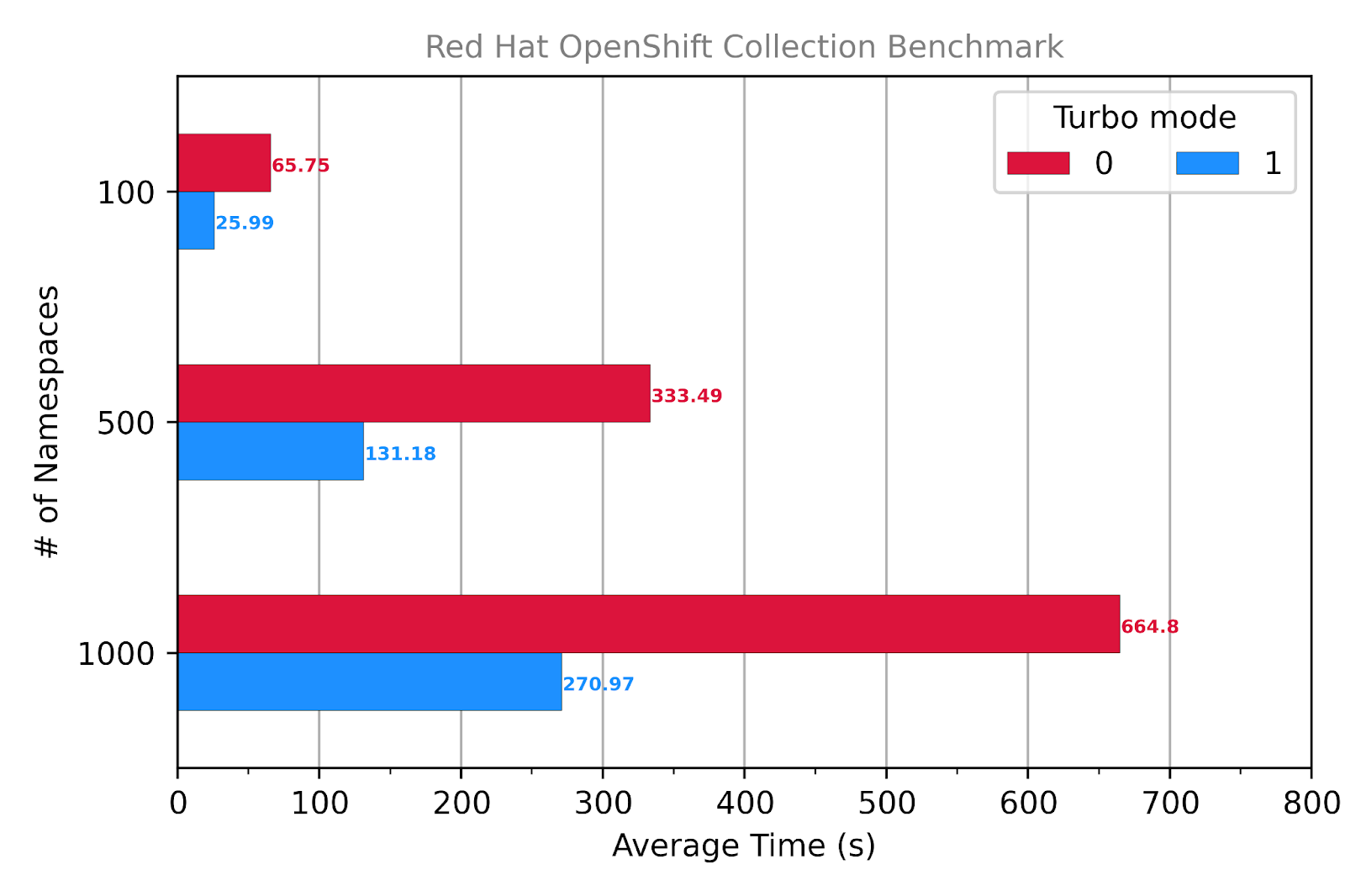
The following figure shows the results obtained when creating 100, 500 and 1,000 namespaces. We can see that using Turbo mode significantly reduces the average response time by ~60% overall.
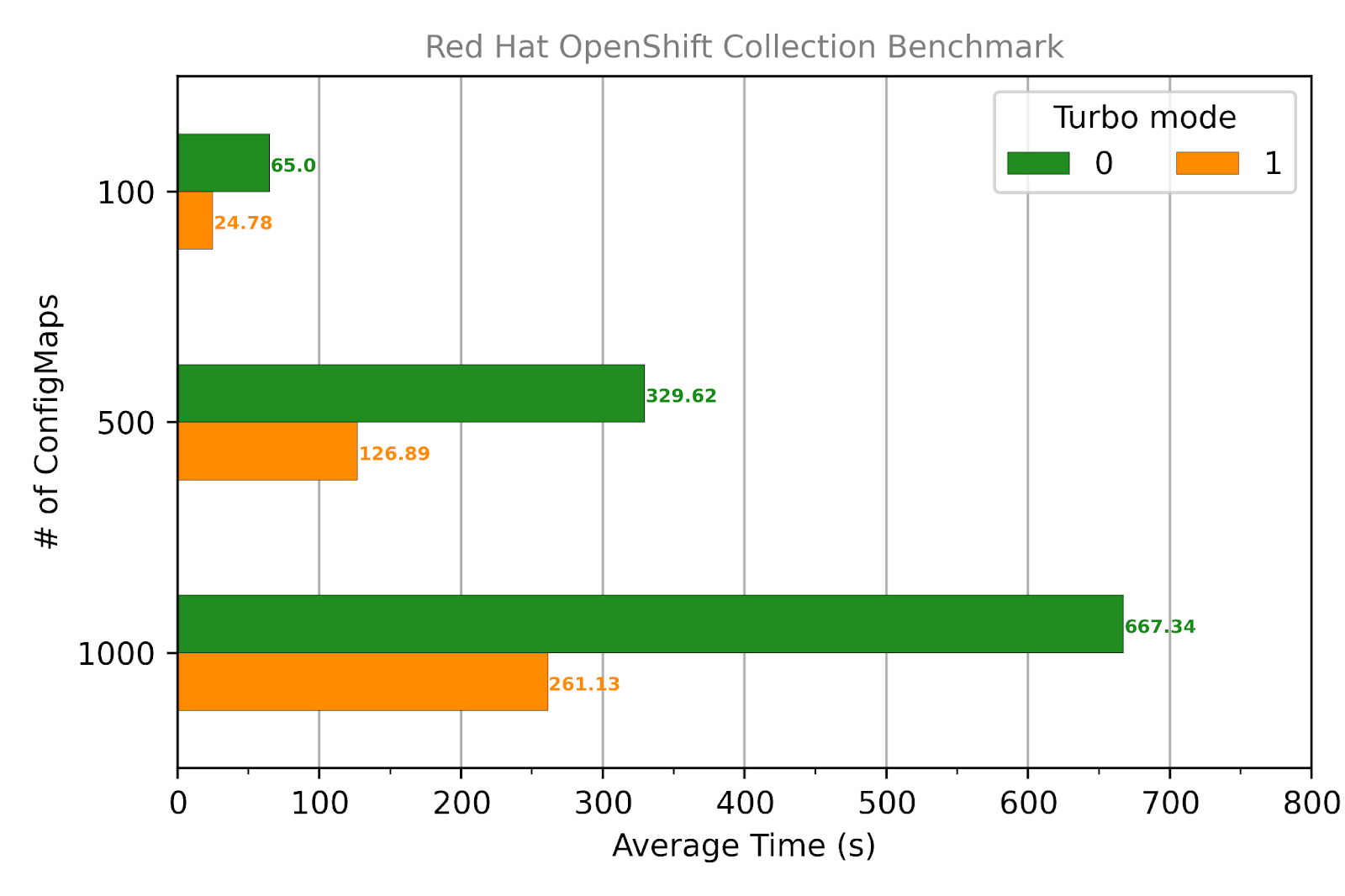
The results are consistent with our first test: Turbo mode gives ~61% faster average response times overall when ConfigMap objects are created.
Conclusion
Combining redhat.openshift Collection with Turbo mode, Ansible users can better manage applications on OpenShift clusters on existing IT with faster iterations and easier maintenance. While we continue to improve our existing benchmarks, we are excited with the results of our latest findings enabling Turbo mode to speed up running Ansible Playbooks for Red Hat OpenShift.
Want to learn more? Check out our other blogs related to automating Red Hat OpenShift. If you are unfamiliar with Ansible Content Collections, check out our YouTube playlist for everything about Ansible Collections. The videos will get you up to speed in no time.
Also, don’t forget to check out our Automate infrastructure workflows e-book if you want to learn more about building a unified, automated pipeline for infrastructure operations.
- Check out all our E-Books online here.
- Where can I get a trial?
- If you want a trial of Ansible Automation Platform, please visit http://red.ht/try_ansible
- Where can I learn Ansible?
- Are you new to Ansible automation and want to learn? Check out our getting started guide lessons on developers.redhat.com
![]()
Originally posted on Ansible Blog
Author: Alina Buzachis